

Vector + VRL로 완성하는 클라우드 네이티브 Observability 실전 가이드
Vector와 VRL을 활용해 클라우드 네이티브 Observability 파이프라인을 구축하는 방법을 소개했습니다. Kubernetes 배포와 Loki, Elasticsearch, Prometheus 연동까지 실전 예제로 설명했습니다.
#Vector#VRL
73005분
Vector와 VRL을 활용해 클라우드 네이티브 Observability 파이프라인을 구축하는 방법을 소개했습니다. Kubernetes 배포와 Loki, Elasticsearch, Prometheus 연동까지 실전 예제로 설명했습니다.


NOL의 결제 서비스 운영 안정화 방법을 PG 다중화, 결제수단 차단, 이벤트 모니터링 중심으로 정리했습니다. 또한 대시보드와 알림으로 이상 징후를 빠르게 감지하는 운영 방식을 소개했습니다.

플레이스 조회 트래픽 증가로 메인 DB 부담이 커져 Elasticsearch를 조회용 DB로 분산한 사례를 공유했습니다. 조회 DB 선택 이유부터 점진적 도입, 자동 fallback, 운영 팁까지 정리했습니다.

실시간 마케팅을 위해 SNS-Lambda-Kinesis-Flink-DB 파이프라인 PoC를 진행했습니다. 12k RPS 목표를 기준으로 병목을 찾아 SQS 추가와 Flink 최적화로 개선했습니다.


쿠폰 적용 가능 상품을 실시간으로 조회하기 위해 이벤트 기반 반정규화와 Elasticsearch 인덱싱 구조를 구축했습니다. 복잡한 매핑과 갱신 조건을 단순화하고 검색 성능과 운영성을 함께 개선했습니다.


OpenSearch와 Analyzer로 부분 검색, 대소문자 무시, 특수문자 제거 검색을 구현하는 방법을 설명했습니다. 또한 카카오페이손해보험의 검색 서비스 활용 사례도 함께 소개했습니다.


Elasticsearch 사각형 공간 검색에서 Box와 Polygon의 성능을 비교했습니다. 두 방식은 큰 차이 없이 유사했으며, 단순 검색에는 Box를 우선 고려할 수 있었습니다.


자체 제작 데이터베이스 Luft의 탄력성을 높이기 위해 쿼리 히스토리를 활용한 비용 기반 오토스케일러 구현 경험을 공유했습니다. 데이터베이스 스케일링 판단에 히스토리 데이터를 활용하는 접근을 다뤘습니다.
Elasticsearch 기반 로그 저장 구조의 비용과 확장성 한계를 해결하기 위해 Iceberg 기반 Alaska를 도입했습니다. Kafka 로그를 오브젝트 스토리지에 직접 적재하고, 실시간 조회와 장기 보관을 분리해 운영 효율을 높였습니다.

식자재 품목 검색 품질을 높이기 위해 Elasticsearch를 도입하고 분석기, N-gram, Wildcard를 조정한 과정을 정리했습니다. 초성 검색은 ICU 확장을 선택해 유지보수성과 확장성을 함께 고려했습니다.
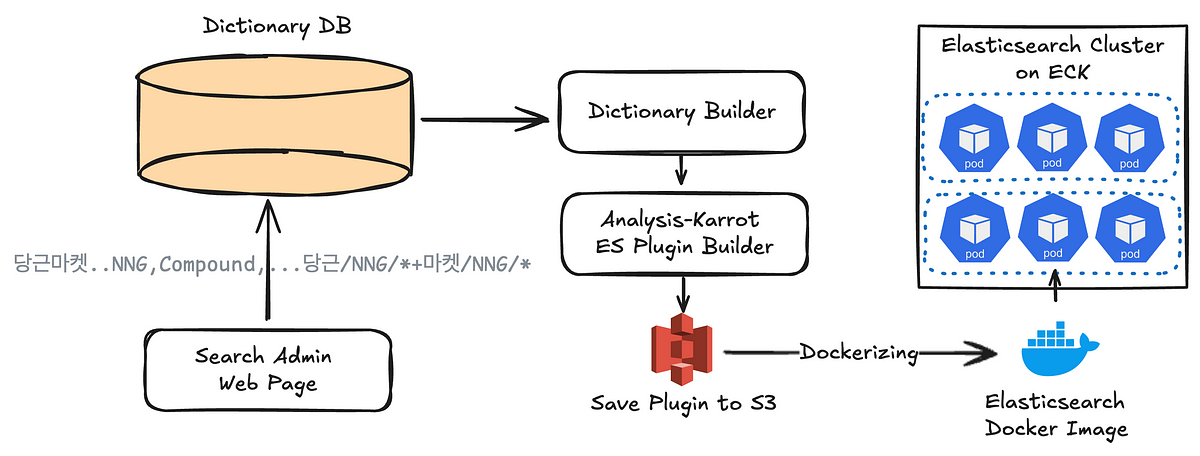
검색 형태소 분석 사전의 배포 과정을 Elasticsearch 재배포 없이 바꾸려는 개선 과정을 다뤘습니다. 메모리 증가 문제를 겪은 뒤 경량화와 버전별 사전 관리로 운영 가능성을 확보했습니다.

DataHub를 그대로 노출하지 않고 OpenSearch와 DB를 직접 활용해 데이터카탈로그에 맞는 검색·리니지·BI 통합 기능을 구현했습니다. 또한 버전업과 수집 성능 문제를 개선해 운영 적합성을 높였습니다.