
CDC 파이프라인 정합성 검사 Spark 잡 개발 - Part 2. Spark 최적화편
CDC 파이프라인 정합성 검사 Spark 잡의 최적화 방법을 다룬 후속 글입니다. 앞선 코드 설계편에 이어 Spark 잡 성능 개선과 운영 관점을 소개했습니다.
#Spark#pipeline
37005분
CDC 파이프라인 정합성 검사 Spark 잡의 최적화 방법을 다룬 후속 글입니다. 앞선 코드 설계편에 이어 Spark 잡 성능 개선과 운영 관점을 소개했습니다.
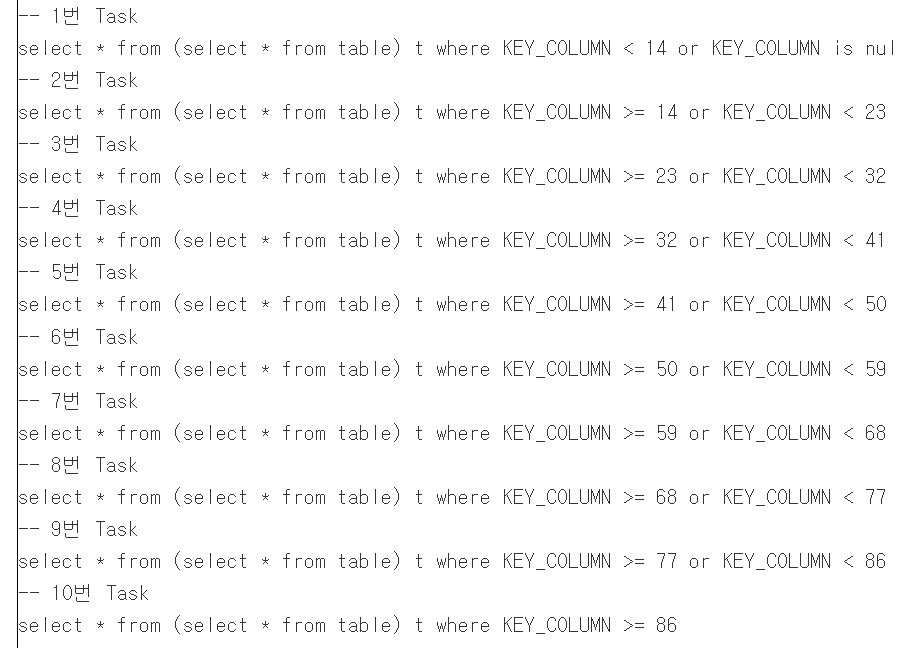

Spark JDBC 병렬처리의 기본 사용법과 파티션 분할 방식의 주의점을 설명했습니다. 소수점 버림으로 인한 skew를 줄이기 위해 upperBound 설정과 컬럼 분포 점검이 필요했습니다.

Spark에서 Rest API 데이터를 수집하는 두 가지 방법을 비교했습니다. 단순 requests 방식과 Spark UDF 방식의 장단점 및 대량 데이터 처리 시 고려점을 설명했습니다.
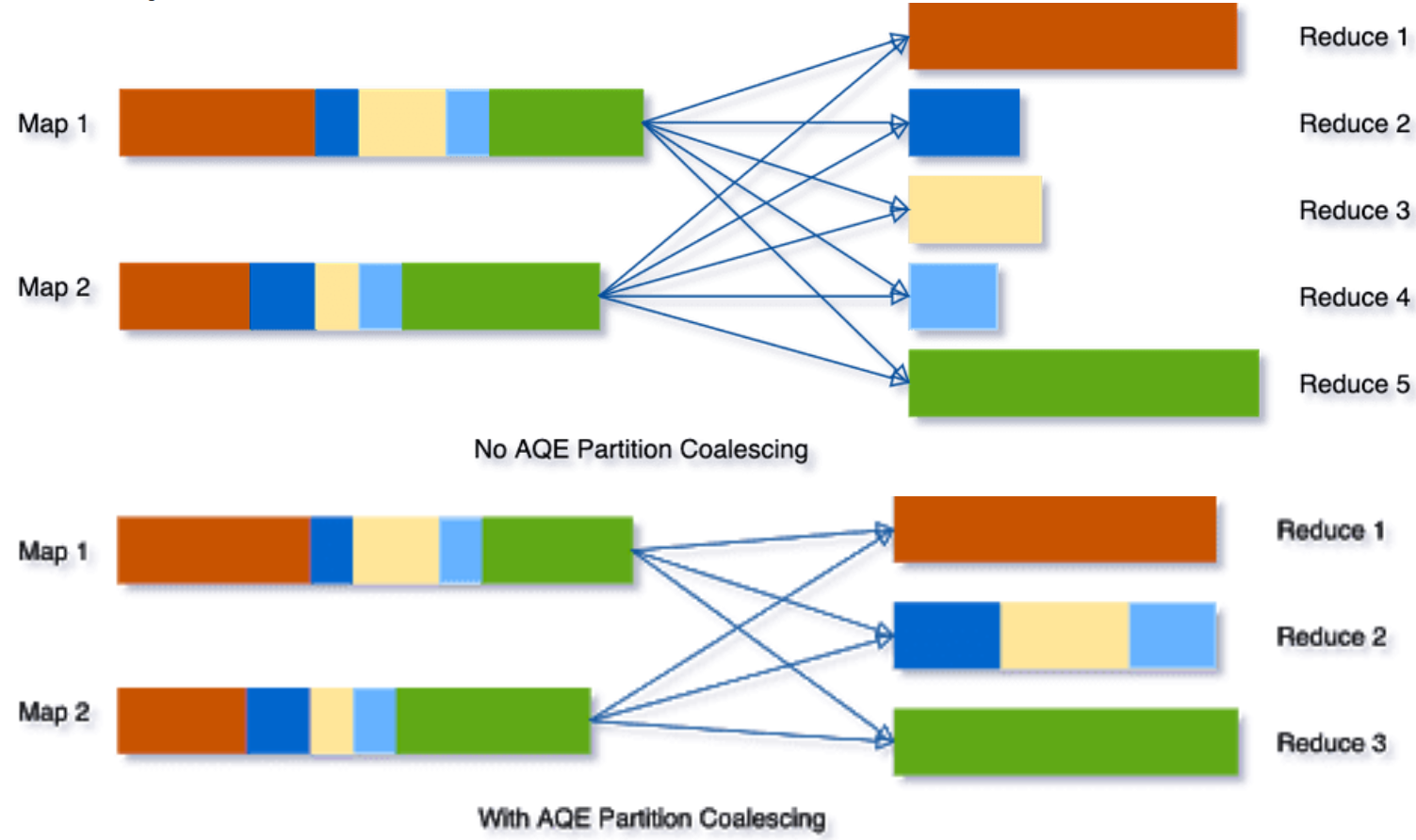
Spark 3.0의 AQE와 coalescePartitions로 셔플 파티션을 동적으로 최적화하는 내용을 소개했습니다. 셔플 파티션 크기에 따른 성능 저하 문제와 파티션 병합 방식도 설명했습니다.
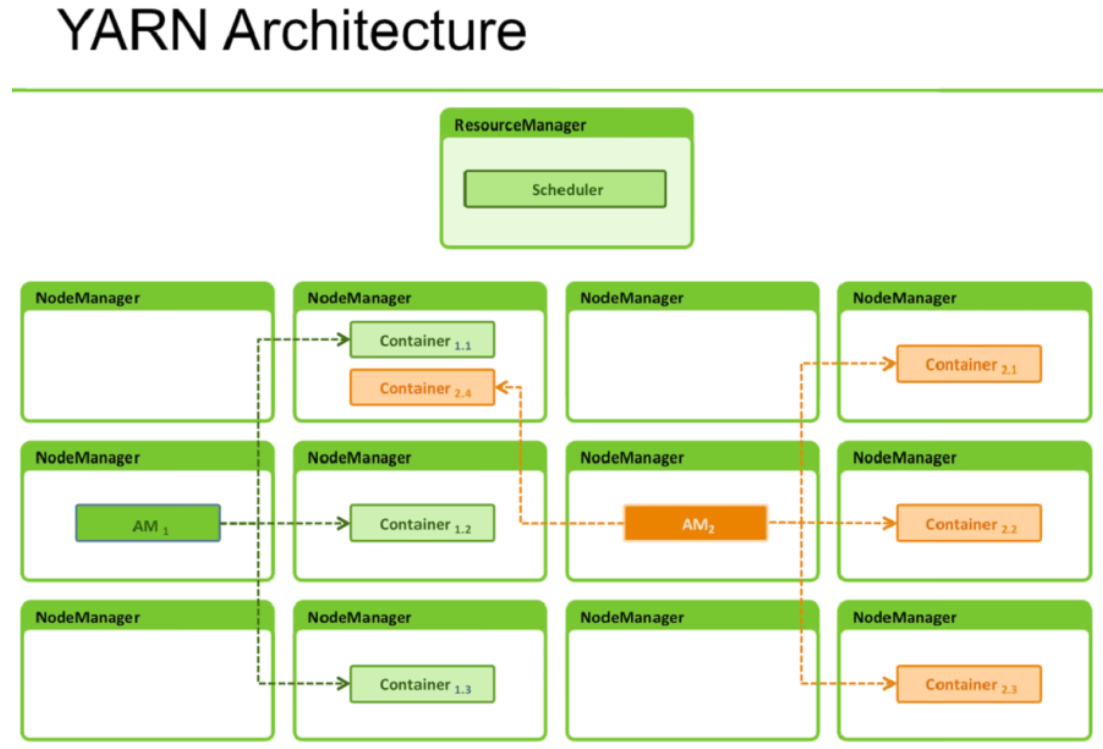
YARN 라벨링으로 Spark의 AM과 Executor를 서로 다른 노드에 배치하는 방법을 소개했습니다. EMR에서 Spot Instance 사용 시 발생하는 장애와 비용 문제를 완화하는 구성도 설명했습니다.
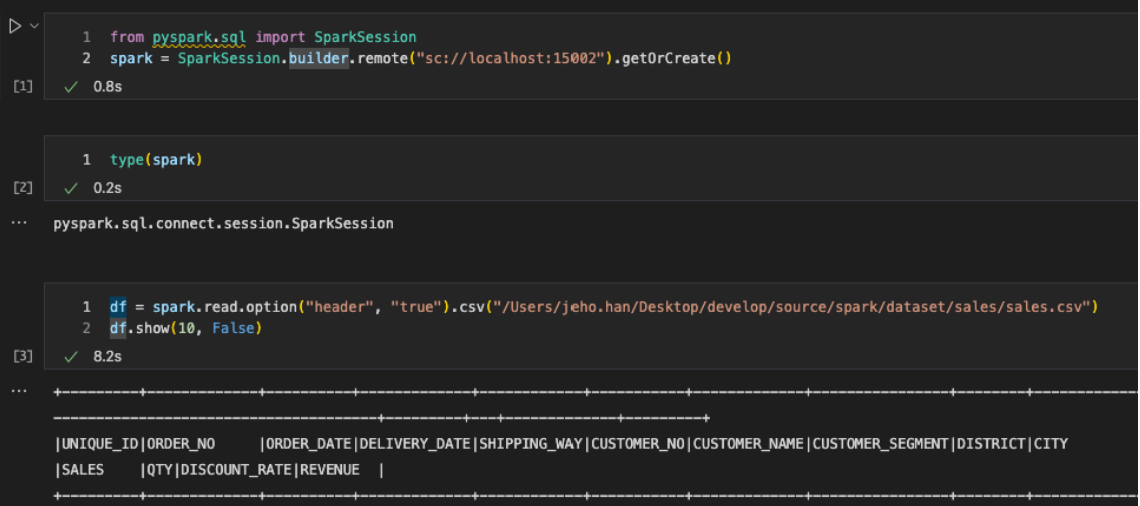
Spark의 원격 연동 한계를 보완하는 Spark Connect의 등장 배경과 동작 방식을 소개했습니다. 서버·클라이언트 환경을 구성해 Jupyter Notebook에서 실제 연결과 실행을 확인했습니다.
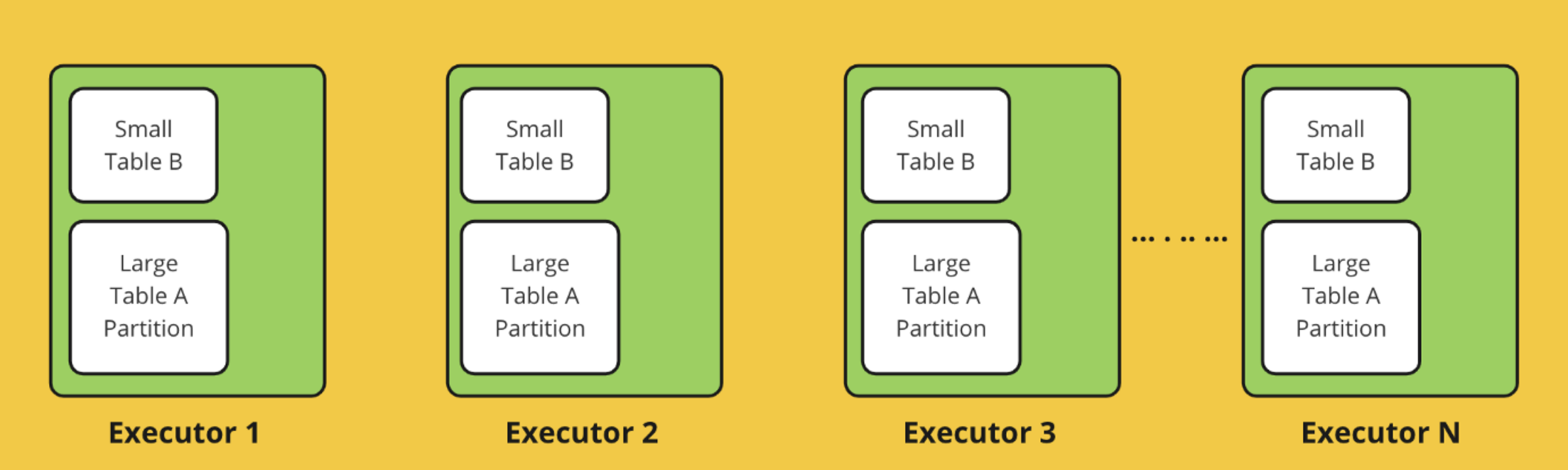
Spark의 Broadcast 기능으로 셔플을 줄이고 join 성능을 높이는 방법을 소개했습니다. 작은 데이터셋에는 자동 broadcast 감지와 설정 조건도 함께 설명했습니다.
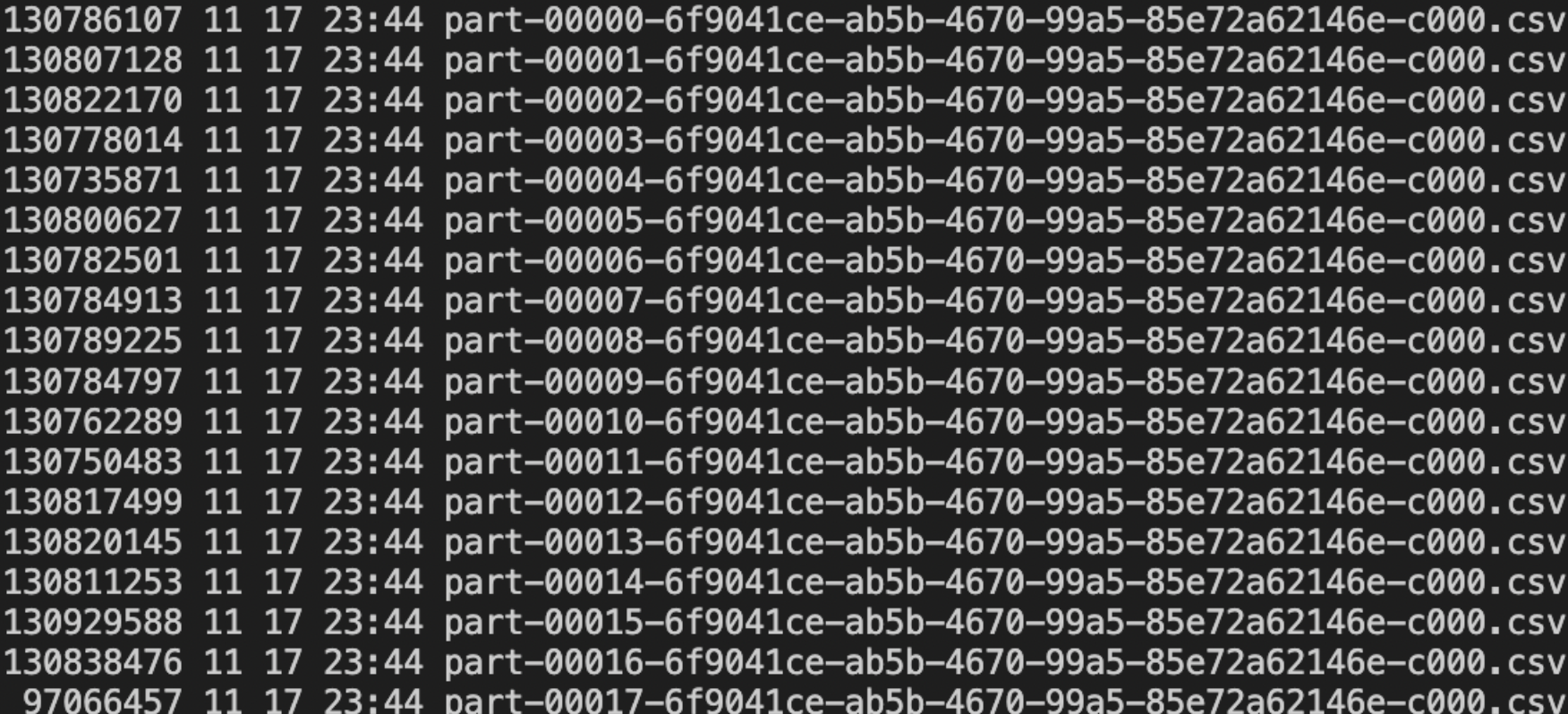
Spark에서 파티션이 병렬성, 메모리, 파일 수에 미치는 영향을 설명했습니다.\n입력·출력·셔플 파티션 설정을 조정해 성능을 최적화하는 방법을 소개했습니다.
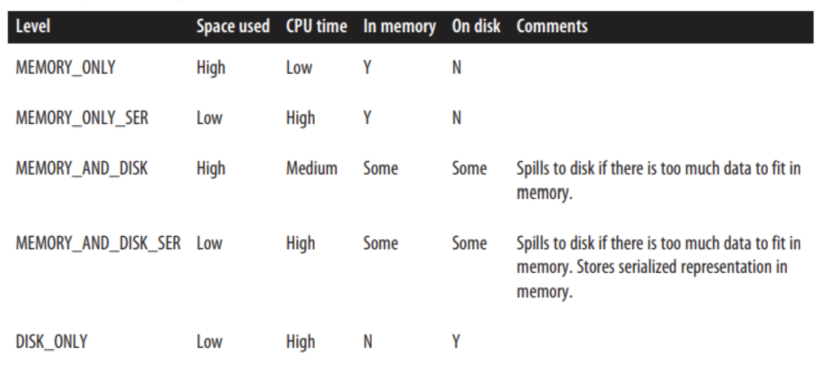
Spark의 Cache와 Persist 개념과 사용 시 주의점을 설명했습니다. 메모리 부족으로 인한 spill over를 줄이는 대응 방법도 소개했습니다.
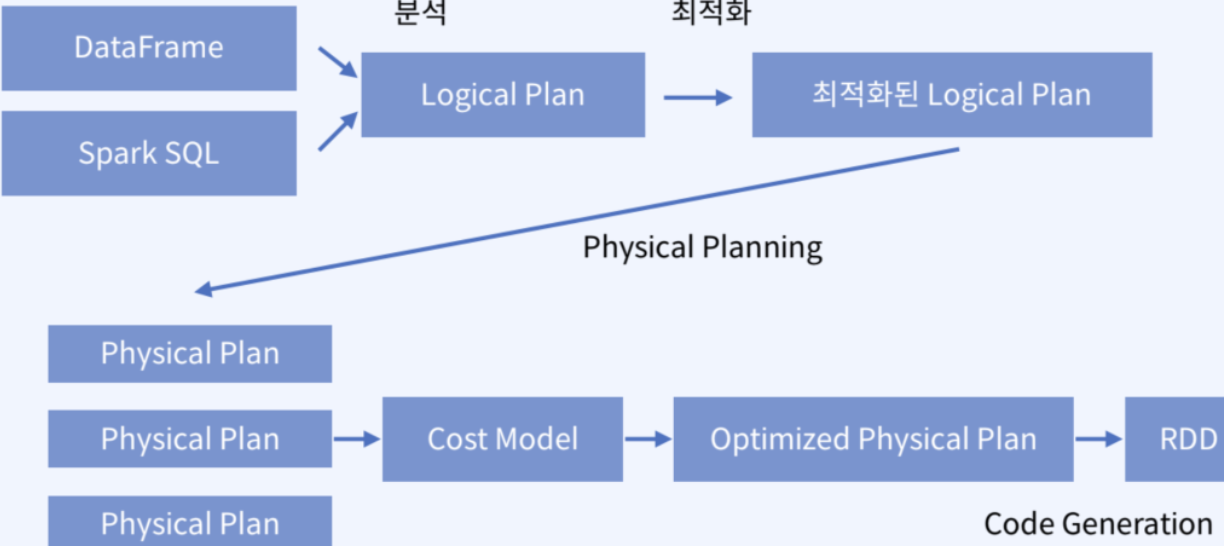
Spark의 동작 방식과 Catalyst, Tungsten 최적화 역할을 소개했습니다. 논리 계획과 물리 계획, Predicate Pushdown 같은 핵심 개념을 설명했습니다.
![[BigData] Spark 개요 정리](https://bespin-wordpress-bucket.s3.ap-northeast-2.amazonaws.com/wp-content/uploads/2025/03/image-10.png)
Spark의 개요와 주요 구성요소, 장점을 정리한 글입니다. 대용량 데이터 처리에서 Pandas보다 Spark가 더 적합한 성능 사례도 비교했습니다.


Amazon S3 Tables의 발표 내용과 서비스팀 확인 사항을 정리한 글입니다. 분석 워크로드 성능 향상, 자동 유지보수, 비용과 한계를 함께 살펴보았습니다.