카프카 파티션 개수 산정식 설계 여정

카프카 파티션 개수 산정식 설계 여정
Kafka 파티션 수를 처리량과 컨슈머 catch-up 기준으로 계산하는 산정식을 정리했습니다. 운영 환경 실측값을 반영해 토픽별 초기 파티션 수를 일관되게 정하는 방법을 제안했습니다.
#Kafka#partition
0005분
Kafka 파티션 수를 처리량과 컨슈머 catch-up 기준으로 계산하는 산정식을 정리했습니다. 운영 환경 실측값을 반영해 토픽별 초기 파티션 수를 일관되게 정하는 방법을 제안했습니다.
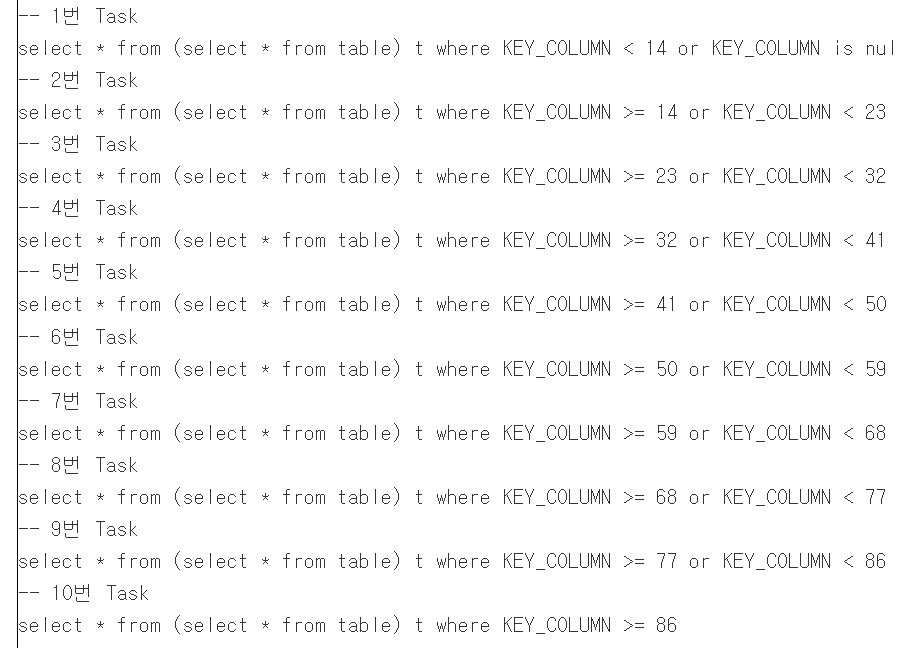

Spark JDBC 병렬처리의 기본 사용법과 파티션 분할 방식의 주의점을 설명했습니다. 소수점 버림으로 인한 skew를 줄이기 위해 upperBound 설정과 컬럼 분포 점검이 필요했습니다.
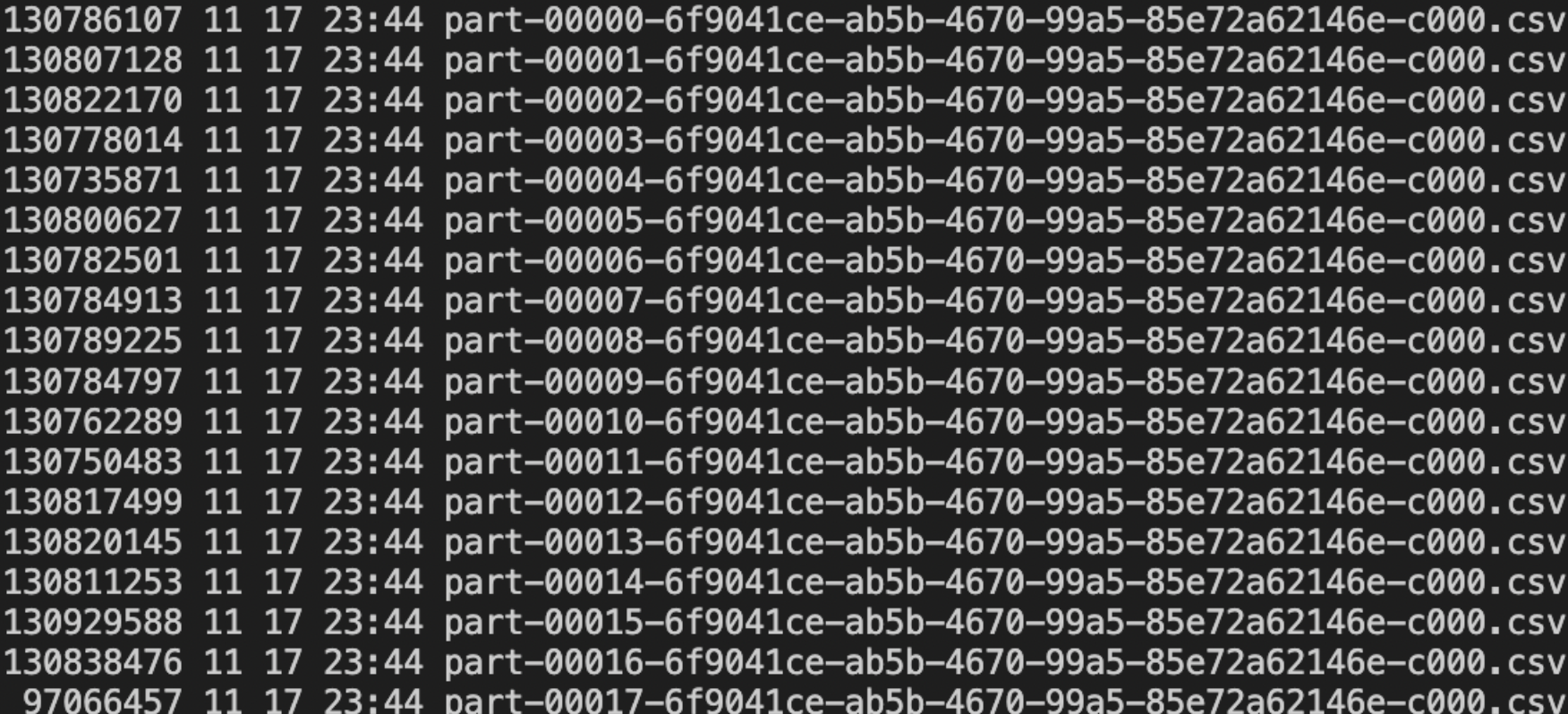
Spark에서 파티션이 병렬성, 메모리, 파일 수에 미치는 영향을 설명했습니다.\n입력·출력·셔플 파티션 설정을 조정해 성능을 최적화하는 방법을 소개했습니다.