12
AI 요약
이 글은 AI가 원문을 분석하여 핵심 내용을 요약한 것입니다.
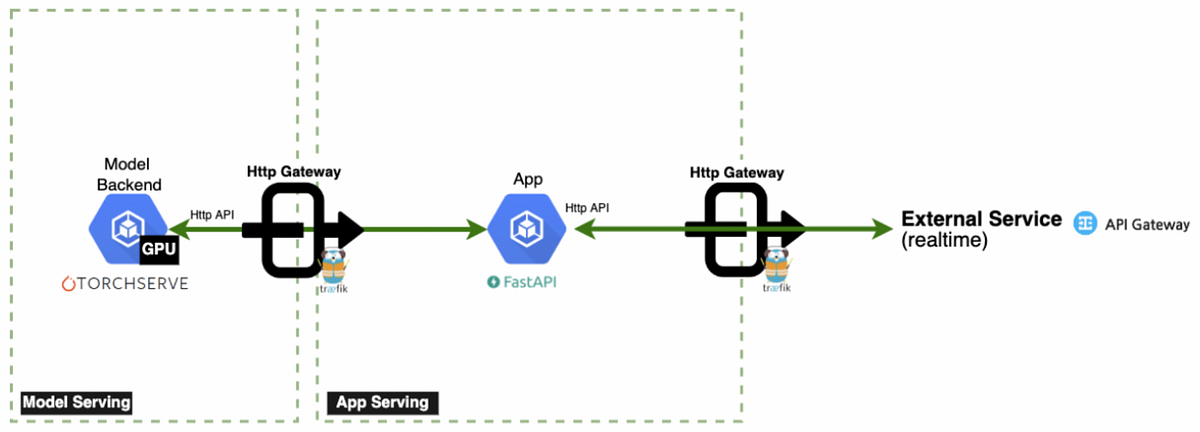
왓챠 추천 서비스의 MLOps 적용기
왓챠 ML팀은 기존 추천 시스템의 문제점을 해결하기 위해 독립적인 추론 서버를 구축했습니다.
기존 시스템의 문제점
기존 시스템은 Monolithic 구조로, 특정 로직의 수정 시 전체 서비스 배포가 필요했습니다.
- PyTorch JNI의 업데이트 지연
- 모델 추론의 비효율성
추론 서버 구축의 필요성
추론 서버는 모델 서빙과 모니터링을 개선하여 효율성을 높였습니다.
요구사항
- PyTorch 지원
- HTTP/gRPC 프로토콜
- 모니터링 용이성
최적화 노력
추론 속도와 네트워크 비용을 최소화하기 위한 다양한 최적화 기법이 적용되었습니다.
모델 경량화
- 가지치기
- 양자화
- 지식 증류