14
AI 요약
이 글은 AI가 원문을 분석하여 핵심 내용을 요약한 것입니다.
ML GPU 모델 서버를 CPU 서버로 전환한 경험
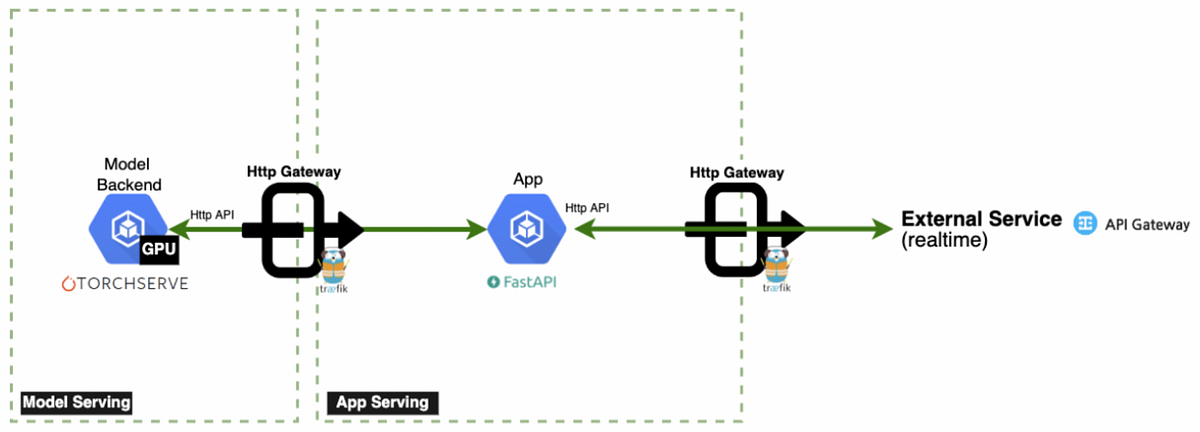
이 게시물은 GPU 기반 ML 모델 서버를 CPU 서버로 전환하면서 성능 저하 없이 서비스 품질을 유지하고 비용 절감을 이룬 경험을 공유합니다.서비스 아키텍처 및 문제점
- App Server에서 CPU 집약적 전처리 및 후처리 수행, Model Server는 순수 추론만 담당
- CPU 전환 후 3배의 pod 증설에도 GPU 대비 10배 낮은 처리량과 10배 느린 응답 시간 발생
- worker 수 증가 시 오히려 성능 악화와 높은 지연 시간 문제 발생
개선 방안
- PyTorch thread 설정 최적화 및 Intel IPEX 도입으로 CPU 코어 핀닝 및 병목 완화
- Knowledge Distillation을 활용해 모델 경량화 및 정확도 유지
- 트래픽 미러링을 통한 장기간 검증 후 프로덕션 적용
성과
- CPU 서버에서 처리량 3~7배 증가, latency 대폭 감소
- 한국 및 일본에서 15대 GPU 자원 절약 및 연간 약 4억원 비용 절감

