
다나와 웹 트래픽 로그 데이터 분석 시스템 도입기
다나와 웹 트래픽 로그 데이터 분석 시스템 도입기
다나와 웹 트래픽 로그 분석용 내부 서비스를 도입한 과정을 정리했습니다. 유비쿼터스 언어 정리부터 Opensearch 선택, 필터링과 검증까지의 흐름을 설명했습니다.
#Elasticsearch#AWS
17005분
새로운 기술 블로그가 추가되었어요
다나와 웹 트래픽 로그 분석용 내부 서비스를 도입한 과정을 정리했습니다. 유비쿼터스 언어 정리부터 Opensearch 선택, 필터링과 검증까지의 흐름을 설명했습니다.


AWS re:Invent 2023 현지 참석 경험과 행사 운영 방식을 소개했습니다. AI/ML 중심 흐름과 클라우드 비용 최적화 관점을 인상적으로 정리했습니다.


AWS RDS MySQL 운영 중 메모리 문제로 장애가 발생한 사례를 소개했습니다. 높은 트래픽 환경에서의 원인과 해결 과정을 다루는 글입니다.
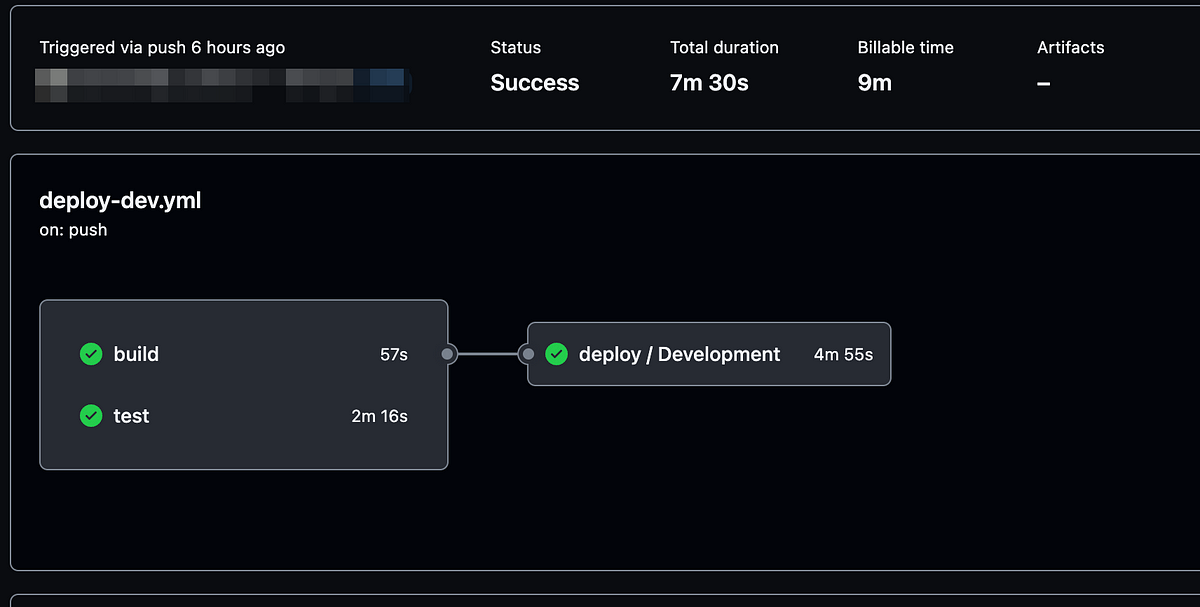

GitHub Actions로 백엔드팀의 일부 CI/CD를 자동화하고, Reusable workflow와 Composite action으로 공통 작업을 재사용했습니다. 또한 캐시와 Marketplace 액션을 활용해 배포 편의성과 운영 효율을 높였습니다.

Karpenter를 도입해 EKS 노드 확장 속도를 높이고 비용 최적화를 시도했습니다. 스파크성 트래픽과 Spot 운영 이슈를 보완하며 안정성과 효율을 함께 개선했습니다.


AWS MSK Connect와 Kafka 기반 CDC 운영 전략을 정리한 글입니다. 장애 대응, 데이터 경량화, DLQ, 모니터링 설정까지 실무 운영 포인트를 소개했습니다.


Redis 사용량을 줄여 ElastiCache 메모리와 비용을 크게 절감한 최적화 사례를 정리한 글입니다. 최적화 대상 탐색부터 이주 과정, 추가 개선 여지까지 소개합니다.

신규 백오피스의 SPA 성능 저하를 코드 스플리팅, Nginx 압축, 정적 캐싱으로 개선했습니다.\n브라우저 API 캐싱과 Vuex를 함께 사용해 로딩 시간과 중복 호출을 줄였습니다.

Redis Worker의 한계를 보완하기 위해 RabbitMQ를 도입한 사례를 소개했습니다. 행사성 트래픽과 대량 발급 처리에서 안정성과 운영 편의성을 개선했습니다.

AWS RDS 모니터링을 위해 CloudWatch Dashboard를 직접 구성하는 방법을 소개했습니다. 가로 임계값과 이상 탐지를 더해 상태 판단을 쉽게 만드는 과정을 설명했습니다.

SK플래닛의 클라우드 기반 검색 시스템 구조와 주요 기능을 소개했습니다. 또한 ChatGPT 이후 대화형 검색으로의 확장 가능성을 함께 살펴봤습니다.
SK플래닛의 Elasticsearch 기반 공용 검색 시스템 구조와 기능을 소개했습니다. 또한 ChatGPT 이후 대화형 검색으로의 확장 가능성을 함께 살펴보았습니다.