사내 AI 에이전트 개선기

사내 AI 에이전트 개선기
사내 AI 에이전트의 컨텍스트 비용과 안전성 문제를 줄이기 위해 v2 구조와 런타임 가드레일을 재설계했습니다. 파일, 채널, 스킬을 필요한 순간에만 제한적으로 읽도록 바꿨습니다.
#OpenAI Agents SDK#prompt caching
0005분
사내 AI 에이전트의 컨텍스트 비용과 안전성 문제를 줄이기 위해 v2 구조와 런타임 가드레일을 재설계했습니다. 파일, 채널, 스킬을 필요한 순간에만 제한적으로 읽도록 바꿨습니다.

Iceberg 운영에서 스냅샷 폭증과 Small File 문제를 어떻게 다뤘는지 정리했습니다. 작업 이력 관리와 메인터넌스 정책으로 비용과 성능을 개선한 사례입니다.


AWS 공간 데이터 관리로 건물 검사 결과를 공간 참조 데이터로 구조화하는 방법을 소개했습니다. 이미지와 메타데이터, 추론 결과를 연결해 장기 보존과 재분석 가능성을 높였습니다.

기존 상품명 중심 검색의 한계를 해결하기 위해 Amazon Bedrock Knowledge Bases 기반 자연어 검색 시스템을 구축했습니다. 하이브리드 검색과 메타데이터 필터링, 병렬 처리로 정확도와 응답 속도를 개선했습니다.

AWS Athena로 ELB/ALB 액세스 로그를 분석하는 테이블 생성 방법을 정리했습니다. 로그 활성화와 S3 설정, 파티션 프로젝션 예시까지 함께 소개했습니다.

Deep Insight의 프로덕션 전환을 하네스 엔지니어링 관점에서 정리했습니다. 에이전트 추론, 코드 실행, 저장소, 네트워크를 분리해 안정성과 보안을 높였습니다.
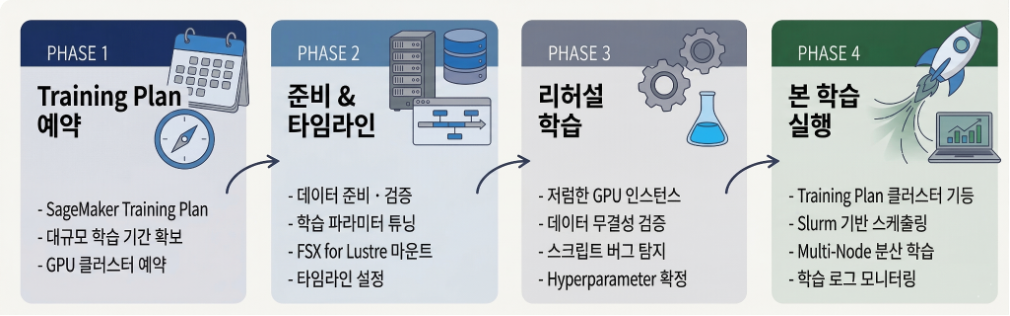
슈퍼브에이아이가 SageMaker HyperPod로 ZERO 모델의 대규모 분산 학습 효율을 높인 사례를 소개했습니다. 저가 리허설과 데이터 사전 로드로 비용과 학습 지연을 줄였습니다.

AWS 미디어 서비스와 TwelveLabs를 결합해 준실시간 비디오 분석 파이프라인을 구성하는 방법을 정리했습니다. 서버리스와 서버 기반, Kinesis Video Streams 활용 사례까지 함께 소개했습니다.

Strands Agents SDK로 TwelveLabs와 AWS 서비스를 결합한 에이전틱 비디오 엔진 구현 방식을 소개했습니다. 단일 에이전트와 멀티 에이전트 구조로 영상 검색, 요약, 자막 처리 흐름을 구성했습니다.

AWS Lambda와 Amazon Bedrock, Claude Agent SDK로 멀티 에이전트 Orchestrator-Worker 구조를 구현하는 방법을 소개했습니다. S3 공유 저장소와 Sonnet/Opus 분리를 통해 제약 대응과 비용 최적화를 함께 다뤘습니다.
클라우드 비용 최적화를 위해 자동 라벨링 시스템을 구축한 사례를 다뤘습니다. 수동 태깅의 한계를 자동화와 운영 지표로 개선했습니다.
DynamoDB Export/Glue/Import로 UserBadge를 분리해 16억 건 규모 마이그레이션을 수행했습니다. 비용은 36% 줄고 시간은 7일에서 약 6시간으로 단축했습니다.