80TB 데이터 비용 10배 절감기: DynamoDB에서 Apache Iceberg로의 여정 - Part 2

80TB 데이터 비용 10배 절감기: DynamoDB에서 Apache Iceberg로의 여정 - Part 2
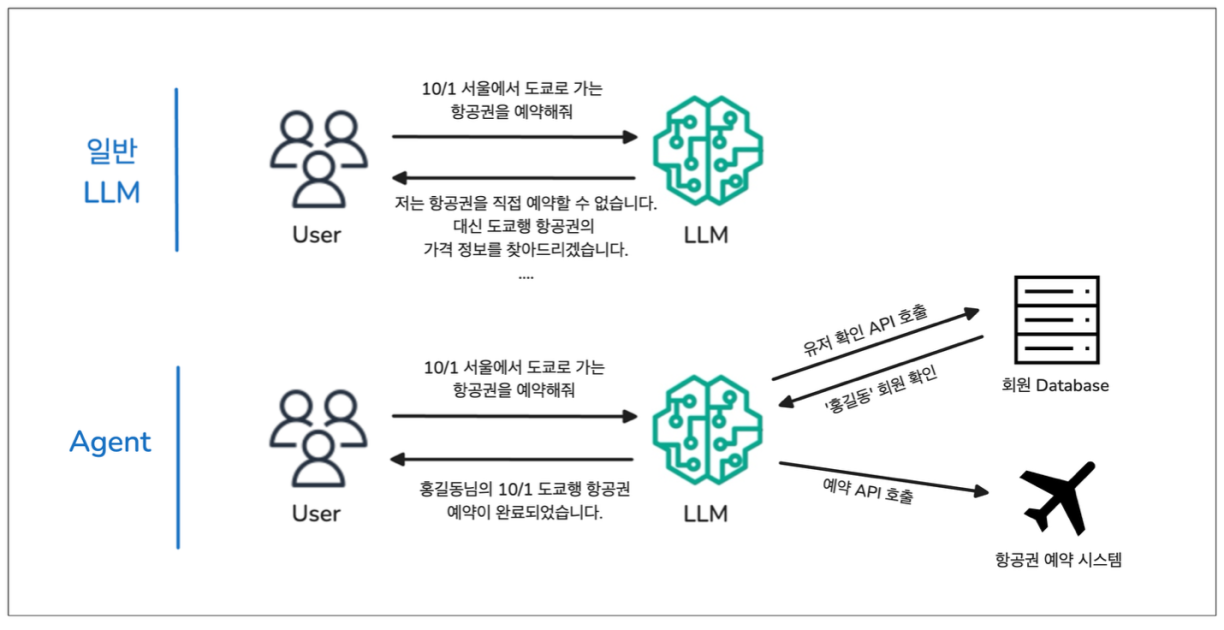
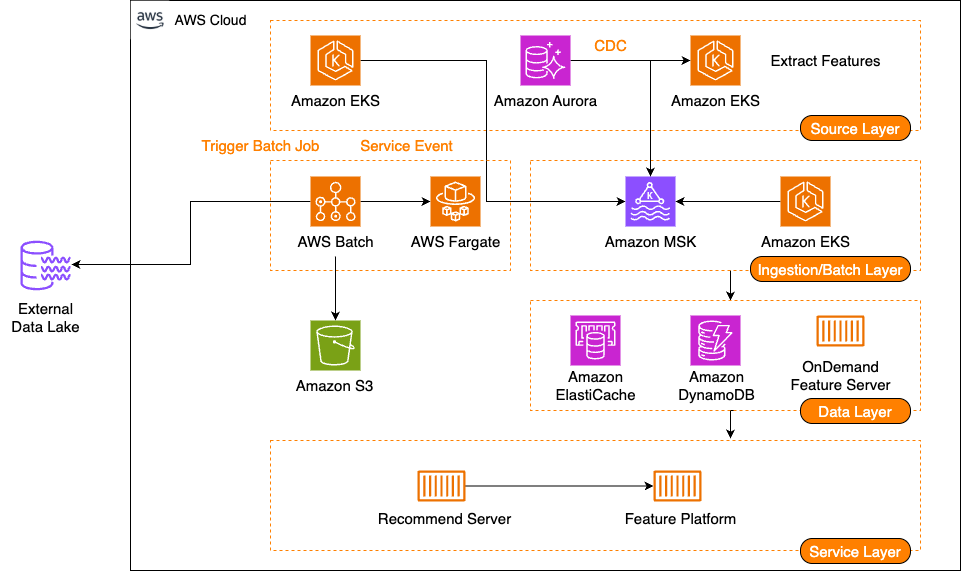
DynamoDB+S3 이중 저장을 Iceberg 단일 테이블로 통합해 비용을 약 91.5% 절감했습니다. 조회 성능과 서빙 안정성도 함께 개선하고, 컴팩션과 조회의 균형 중요성을 정리했습니다.
#DynamoDB#Apache Iceberg
0005분