
AI Agent 개발 경진대회

AI Agent 개발 경진대회
AI Agent 개발 경진대회 안내문입니다. 참가 대상, 주제, 평가 기준, 시상 내역과 신청 방법을 공지했습니다.
#LLM#회의
58005분
새로운 기술 블로그가 추가되었어요
AI Agent 개발 경진대회 안내문입니다. 참가 대상, 주제, 평가 기준, 시상 내역과 신청 방법을 공지했습니다.


국내 AI 노트 서비스 4종의 전사, 요약, 다국어, 협업 기능을 비교했습니다. 용도에 맞게 선택하면 회의록과 학습 정리를 더 효율적으로 할 수 있습니다.


LLM이 입력을 받아 답변을 생성하기까지의 내부 동작을 6단계로 나눠 쉽게 설명했습니다. 백엔드 개발자가 프롬프트와 활용 방식을 이해하는 데 필요한 핵심 흐름을 정리했습니다.

에이닷 v4.0의 성능을 기능별 지표와 SLO로 나눠 객관적으로 검증했습니다.\nWebView, LLM, 비동기 작업 특성에 맞춘 기준과 측정 절차도 함께 정리했습니다.

LLM 기반 Text-to-SQL의 오류 유형과 빈도를 정리하고, 기존 수리 방식의 한계를 분석했습니다. 규칙 기반 감지와 LLM 보조 수정을 결합한 MapleRepair의 실무적 효과를 소개했습니다.


엔터프라이즈 AI 에이전트는 전통적인 LLM 평가만으로는 충분히 측정하기 어려웠습니다. NEXA는 LLM-as-a-Judge로 도구 정확성과 효율성을 평가하는 방식을 적용했습니다.
엔터프라이즈 AI 에이전트는 전통적 LLM 평가만으로는 성능 측정이 어려워 전용 평가가 필요했습니다. NEXA는 Langfuse의 LLM-as-a-Judge로 도구 정확성과 효율성을 함께 평가했습니다.

Qwen Code에 `Qwen.md` 규칙을 적용해 회사 맞춤형 코드 수정을 유도하는 방법을 소개했습니다. 폐쇄망 환경에서도 규칙 기반 자동 수정을 활용하는 흐름을 보여주었습니다.
![[에이닷 4.0 QE 여정2] SPeCTRA 2.0 - 제5원소 Memory](https://devocean.sk.com/thumnail/2025/9/4/2c31238f96a0283c54b6415ae64ca78f9ec066e2fad0730076c9bef80f3b1956.png)
SPeCTRA 2.0에 Memory를 제5원소로 포함한 배경과 의미를 정리했습니다. 시퀀스·페르소나·시간 기반 검증과 Memory Safety 전략까지 소개했습니다.

Context Engineering을 LLM 성능을 높이는 핵심 역량으로 정리하고 Prompt Engineering과의 차이를 설명했습니다. Cursor AI와 Claude Code 사례를 통해 실무 적용 방식과 컨텍스트 관리 방법을 소개했습니다.

무신사 엔지니어링이 AI 해커톤 무슨사이를 통해 사람과 AI의 협업 문화를 실험했습니다. 경쟁보다 학습을 강조하며 실제 개발과 운영에 AI를 녹여낸 사례를 소개했습니다.
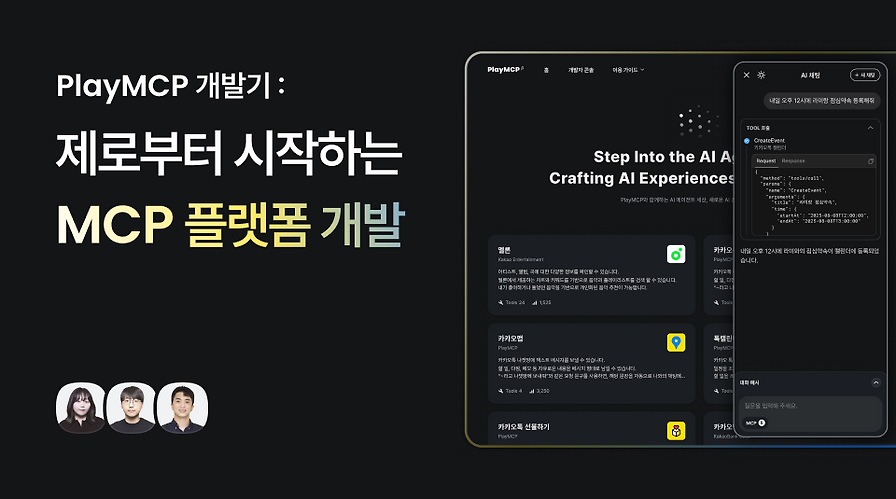

PlayMCP를 제로부터 개발한 소개 글입니다. AI가 자연스러운 대화를 구현하는 흐름 속에서 MCP 플랫폼 개발 배경을 설명합니다.