

Auto 자동차 매뉴얼 특화 RAG 데모 시스템 개발
자동차 매뉴얼 검색을 위한 도메인 특화 RAG 데모 시스템을 개발했습니다. LLM과 메타 정보를 결합해 출처가 보이는 응답과 더 나은 사용자 경험을 제공했습니다.
#RAG#LLM
38005분
자동차 매뉴얼 검색을 위한 도메인 특화 RAG 데모 시스템을 개발했습니다. LLM과 메타 정보를 결합해 출처가 보이는 응답과 더 나은 사용자 경험을 제공했습니다.

LLM 파인튜닝에서 Optimizer, 학습률, 스케줄러, Warmup, 정밀도 선택 기준을 실험 결과로 정리했습니다.메모리와 안정성을 함께 고려해 AdamW 계열과 BF16, 1e-4 근처 학습률을 중심으로 검증하는 방법을 제시했습니다.


사내 AI 챗봇 서비스를 Next.js 템플릿 기반으로 구축하고, Azure OpenAI와 GraphQL 도구 연동을 확장한 과정을 공유했습니다. 배포와 필터링, 컨텍스트 초과 같은 문제를 해결하며 내부 구성원용 서비스로 운영한 사례입니다.


AWS re:Invent 2024에서 소개된 금융 회사의 생성형 AI 구축 사례를 다룬 글입니다. AWS 기반 적용 사례의 개요를 간단히 소개했습니다.

DeepSeek-R1의 강화 학습 기반 추론 향상 방식과 지식 증류 전략을 정리했습니다. 또한 API 활용, 소형 모델 성능, 향후 개선 과제까지 함께 살펴봤습니다.

GPU 메모리 사용을 줄이기 위한 그레이디언트 누적, 체크포인팅, ZeRO, LoRA, QLoRA를 정리했습니다. 각 기법이 절감하는 메모리 영역과 적용 효과를 예시와 함께 설명했습니다.
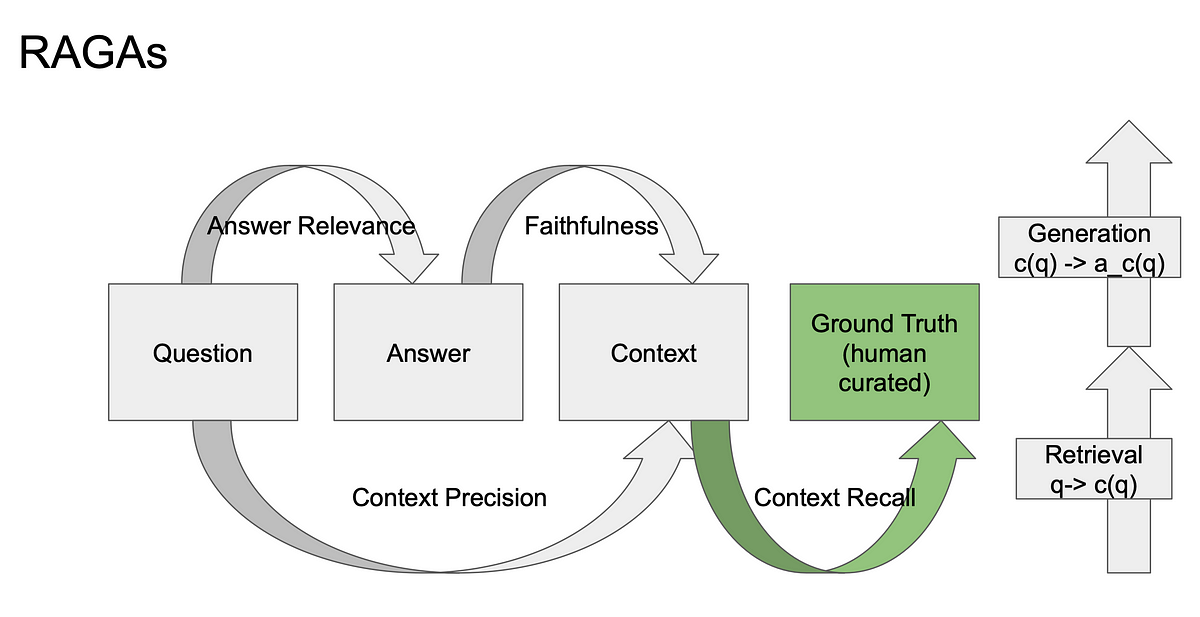

생성형 검색(RAG) 평가의 최근 트렌드와 주요 플랫폼, 지표 변화를 정리했습니다. LC와 RAG의 비교 결과를 통해 질문 유형별 적합한 접근도 살펴봤습니다.

X

vLLM을 활용한 LLM 서빙 최적화 방법을 배치 전략, 어텐션 최적화, 추론 전략으로 나눠 설명했습니다. 온라인 서빙과 오프라인 서빙의 차이와 간단한 구현 예시도 함께 소개했습니다.


산업 현장에 맞는 Vertical AI 에이전트 구현 방식과 설계 원칙을 소개했습니다. Agent Flow와 Autonomous Agent를 조합해 예측 가능한 문제와 예외 상황을 함께 다뤘습니다.

LLM 추론 효율을 높이기 위한 배치 전략과 어텐션 개선 방법을 정리한 글입니다. FlashAttention, 페이지 어텐션, 추측 디코딩의 개념과 장점을 설명했습니다.

LLM 애플리케이션을 직군에 상관없이 쉽게 만들고 배포할 수 있는 환경 구축 사례를 소개했습니다. Prompt Store, Langflow, 자동 배포 구조로 개발과 피드백 주기를 단축했습니다.