

해외파트너센터 개발 오픈기- 3.글로벌 대응을 위한 다국어 처리 작업
해외 파트너 센터에 다국어 처리를 적용한 과정과 i18next 선택 이유를 정리했습니다. Next.js 환경에서의 언어 감지, JSON 관리 방식, 유지보수 포인트도 함께 공유했습니다.
#i18next#react-i18next
117005분
해외 파트너 센터에 다국어 처리를 적용한 과정과 i18next 선택 이유를 정리했습니다. Next.js 환경에서의 언어 감지, JSON 관리 방식, 유지보수 포인트도 함께 공유했습니다.

ChatGPT를 연동한 오글봇으로 게시글 첫 댓글과 대댓글 기능을 구현한 사례입니다.\n프롬프트 조정, 비동기 처리, Function call 연동으로 참여도와 응답 정확도를 높였습니다.
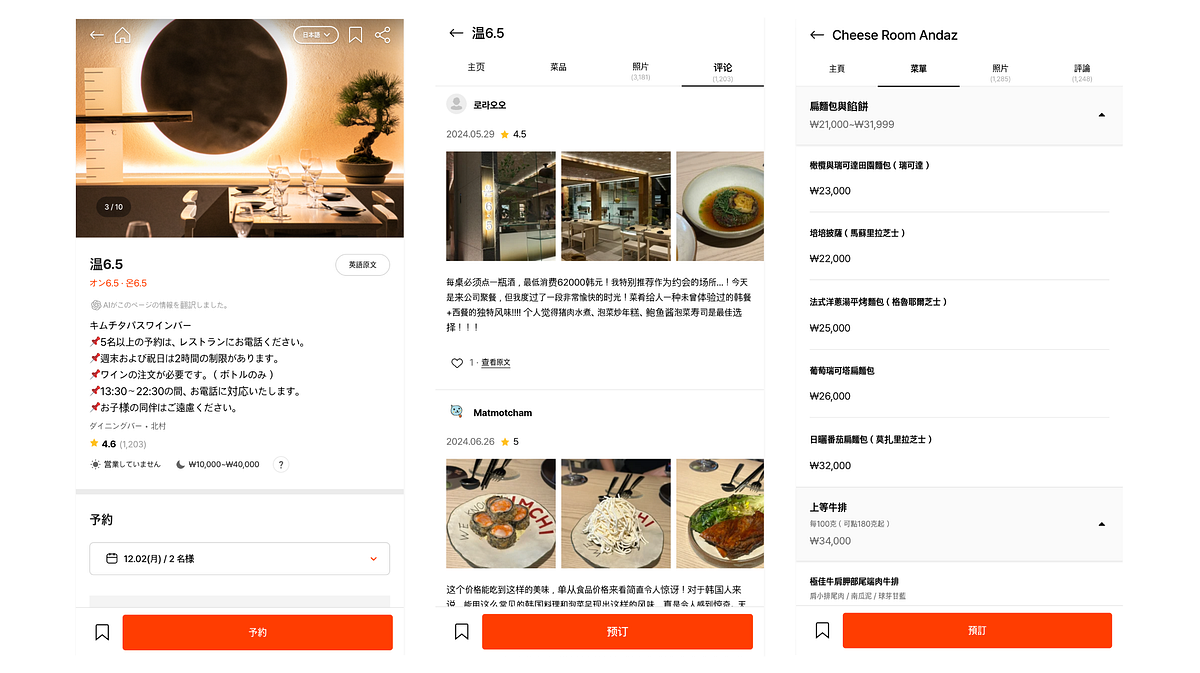

캐치테이블 글로벌은 번역 마이크로서비스와 검수 어드민을 도입해 다국어 레이어를 구축했습니다. 또한 AWS DMS CDC와 Kafka를 활용해 기존 도메인 변경을 중앙에서 번역 요청하도록 설계했습니다.


DevOps 효율을 높이기 위해 Jira, GitLab, Jenkins 데이터를 REST API로 수집하고 PostgreSQL에 저장하는 시각화 전략을 소개했습니다. 라인 차트, 산점도, 테이블을 활용해 현황을 한눈에 보고 분석과 보완을 반복하는 흐름을 제안했습니다.


카프카 커넥트의 내부 오프셋 관리 방식과 REST API 기반 조작 방법을 설명했습니다. 예제로 오프셋을 되돌려 레코드를 다시 처리하는 과정을 보여주었습니다.

REST API가 준비되기 전에도 클라이언트가 테스트할 수 있는 데이터 모킹 도구를 소개했습니다. 복잡한 API 연동과 검증 과정의 커뮤니케이션 비용을 줄인 사례입니다.

MinIO와 Kubernetes로 사내 오브젝트 스토리지 서비스를 구축한 과정을 정리했습니다. S3 호환성과 확장성을 바탕으로 보안, 비용, 운영 효율을 개선했습니다.

하루 6천 개가 넘는 Spark Job을 자동으로 점검하기 위해 Spark Analyzer를 개발했습니다.\nHistory Server 메트릭과 임계치 기반 규칙으로 성능 문제를 탐지하고 알림으로 연결했습니다.

Ktor REST API 서버에서 OAS 스펙을 작성하고 OpenAPI Generator로 모델 코드를 생성하는 방법을 설명했습니다. 생성된 모델을 Ktor 라우트에 연결하고 OpenAPI UI로 스펙을 서빙하는 구성도 함께 다뤘습니다.

검색 대상 문서를 Kafka와 Solr로 색인·서빙하는 플랫폼 구축 과정을 소개했습니다. 기본 검색, 시간 범위 검색, 필터 검색과 성능 검증까지 함께 다루었습니다.