[DAN 24] 데이터 기반으로 지속 성장이 가능한 네이버 검색 FE 시스템 구축하기

[DAN 24] 데이터 기반으로 지속 성장이 가능한 네이버 검색 FE 시스템 구축하기
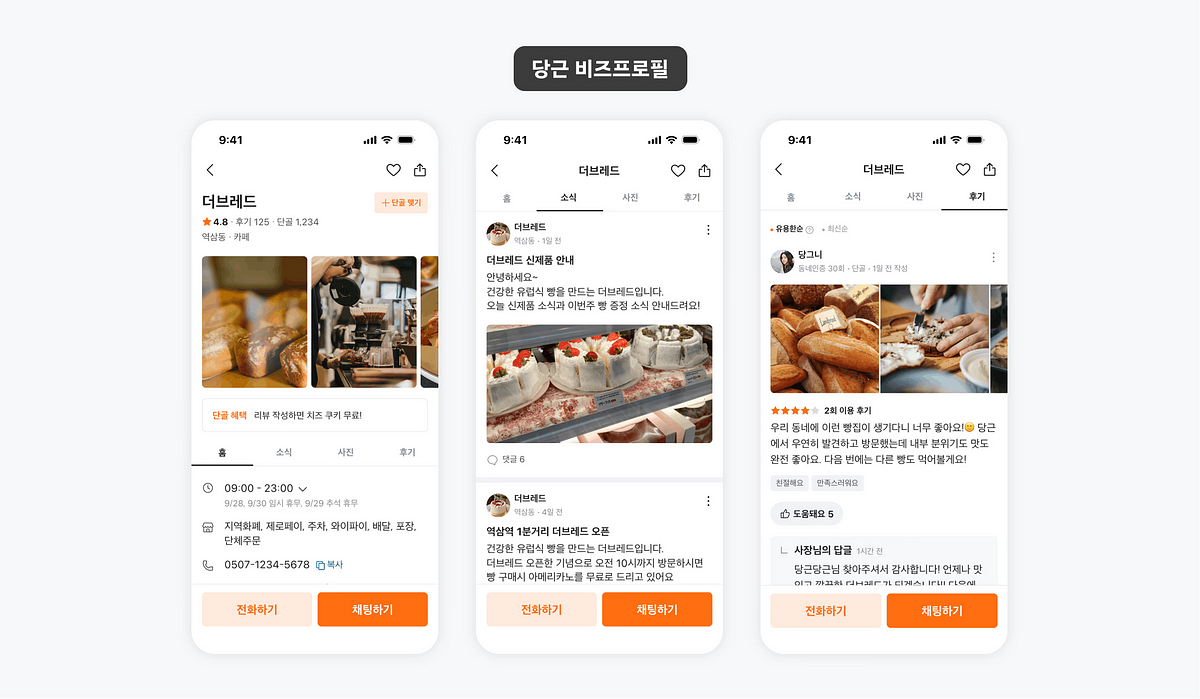
네이버 검색 FE 시스템의 반복 작업과 UI 중복, 느린 피드백 문제를 해결하기 위한 구조를 정리했습니다. 서버 주도 UI, 디자인 시스템, 데이터 기반 개선과 Design To Code 자동화를 함께 소개했습니다.
#MSA#서버 주도 UI
39005분
네이버 검색 FE 시스템의 반복 작업과 UI 중복, 느린 피드백 문제를 해결하기 위한 구조를 정리했습니다. 서버 주도 UI, 디자인 시스템, 데이터 기반 개선과 Design To Code 자동화를 함께 소개했습니다.


비동기 메시지 규약이 제각각이라 추적과 유지보수가 어려운 문제를 길드 활동으로 해결했습니다. AsyncAPI와 Code-Gen 도구 WAAX를 도입해 문서화, 정적 검증, 가시화를 함께 개선했습니다.


MSA 기반 미디어 업로드 구조를 재설계해 람다 간 복잡한 호출과 분기 코드를 줄였습니다. 또한 DynamoDB, DocumentDB, Step Functions, Kafka를 활용해 유지보수성을 높였습니다.

토스증권의 Kafka 데이터센터 이중화 개요를 소개하며 Active-Active와 Stretched Cluster를 비교했습니다. 가용성과 성능을 고려해 Active-Active를 선택하고 DNS와 Offset Sync 전략을 설명했습니다.

현대자동차그룹 커넥티드 카 서비스의 글로벌 확장을 위해 가입·개통 시스템 개편 사례를 다뤘습니다. 모놀리식 구조를 MSA 방향으로 전환하는 맥락을 소개했습니다.
GraphQL을 인메모리 QueryFacade로 활용해 복잡한 Aggregator 구조를 정리한 사례를 다뤘습니다. 필요한 의존성만 조회하고 부분 에러 처리와 캐시 제어를 붙여 성능도 개선했습니다.

비동기 메시지 규칙이 제각각이던 레거시 시스템을 통합 이벤트·커맨드·태스크로 분류해 표준화했습니다. Kafka와 Bullmq로 cloud agnostic 인프라를 구성해 CSAP 대응 마이그레이션을 완료했습니다.

은행의 하루 3천만 트래픽 홈 화면을 레거시에서 분리해 새로 개편한 사례를 다뤘습니다. MSA 기반으로 안정적인 홈 서비스 분리를 추진한 여정을 정리했습니다.
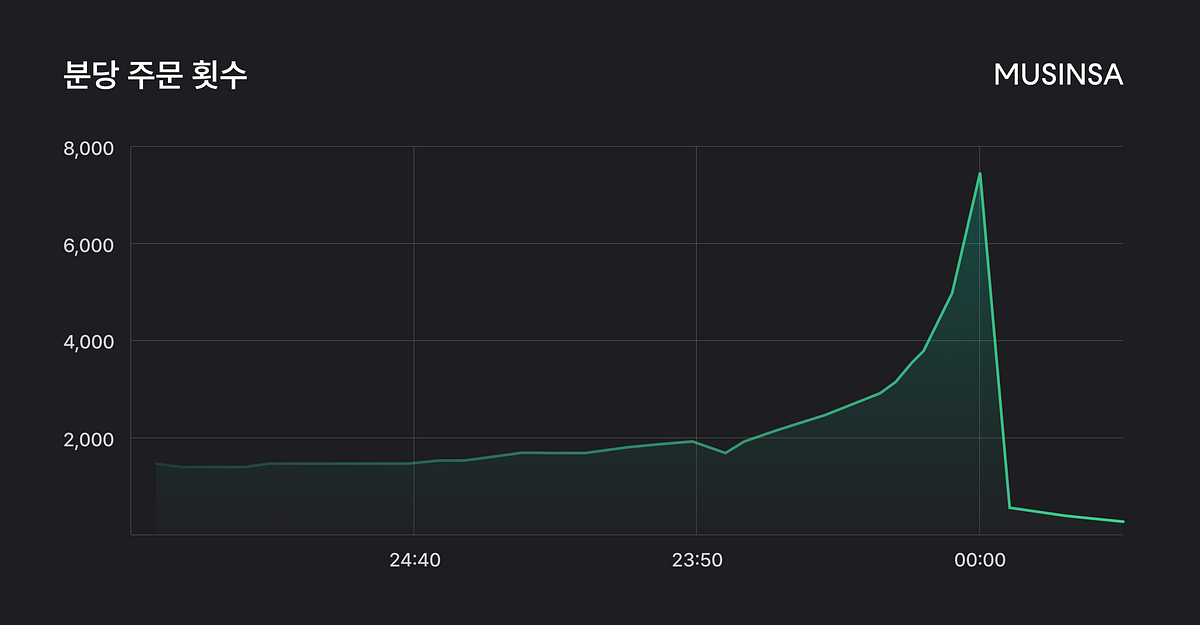
무신사 주문 시스템이 모놀리식에서 MSA, EDA, Kafka, Java 전환까지 단계적으로 개선된 과정을 다뤘습니다. 대규모 트래픽과 이벤트 시즌에서도 안정성과 확장성을 높인 리팩토링 경험을 공유했습니다.


결제탭 피드 서버에서 여러 MSA 콘텐츠를 조립하는 코드 아키텍처를 공유했습니다. 유연한 구조를 찾기 위한 설계 흐름이 핵심입니다.


5월 트래픽 폭증에 대비해 RDS 모니터링과 자원 분리 전략을 강화했습니다. 커밋 지연 원인을 찾아 파라미터를 조정해 처리량을 개선했습니다.

분산 네트워크와 마이크로서비스 환경에서 애플리케이션 로그를 수집하고 짝 맞추는 필요성을 다뤘습니다. Serilog를 통해 데이터 수집과 분석을 하는 방향을 소개했습니다.