

MSA 기반 미디어 업로드 고도화: 람다 함수 구조 변경으로 유지보수성 향상
MSA 기반 미디어 업로드 구조를 재설계해 람다 간 복잡한 호출과 분기 코드를 줄였습니다. 또한 DynamoDB, DocumentDB, Step Functions, Kafka를 활용해 유지보수성을 높였습니다.
#MSA#AWS Lambda
26005분
MSA 기반 미디어 업로드 구조를 재설계해 람다 간 복잡한 호출과 분기 코드를 줄였습니다. 또한 DynamoDB, DocumentDB, Step Functions, Kafka를 활용해 유지보수성을 높였습니다.


카프카 컨슈머 처리량을 외부 DB 부하에 맞춰 동적으로 조절하는 방법을 다뤘습니다. Thread.sleep()의 한계와 pause()/resume()을 활용한 리밸런싱 회피 방식을 설명했습니다.

토스증권의 Kafka 데이터센터 이중화 개요를 소개하며 Active-Active와 Stretched Cluster를 비교했습니다. 가용성과 성능을 고려해 Active-Active를 선택하고 DNS와 Offset Sync 전략을 설명했습니다.

운영 로그의 기준을 다시 정리해 실제 장애와 가짜 에러를 구분하는 방법을 다뤘습니다. 알람 노이즈를 줄이고 빠른 인지를 위해 로그 레벨과 임계치를 팀 기준으로 조정했습니다.

프리즘의 메시지 브로커를 SQS, Kafka, RabbitMQ 순으로 바꾼 이유를 정리했습니다. 요구 사항에 맞는 전달 보장과 스케일링, 분배 특성이 선택의 핵심이었습니다.


보험금 청구의 불편함을 줄이기 위해 즉시지급 프로세스를 구축한 사례를 소개합니다. 레거시 분리, 문서 인식 자동화, 워크플로 개선으로 비용과 처리 시간을 크게 줄였습니다.


회원 승급 작업을 수작업에서 AWS Batch 기반 자동화로 전환했습니다. Apache Kafka 도입으로 대용량 동기화 지연도 크게 줄였습니다.
![[if(kakaoAI)2024] 지연이체 서비스 개발기: 은행 점검 시간 끝나면 송금해 드릴게요! (feat. 발표 후기)](https://tech.kakaopay.com/_astro/thumb.14bac5f0_27QJF2.png)
Kafka 기반 지연이체 서비스를 재설계하고 개발한 경험을 공유했습니다. if(kakao) 발표 후기와 함께 지연 처리 구조를 소개했습니다.
Spring Boot와 Java 버전업 과정에서 Gson 직렬화 에러의 원인을 자바 모듈 시스템 변화로 분석했습니다. `LocalDateTime`에 Custom TypeAdapter를 적용해 리플렉션 문제를 우회하고 해결했습니다.
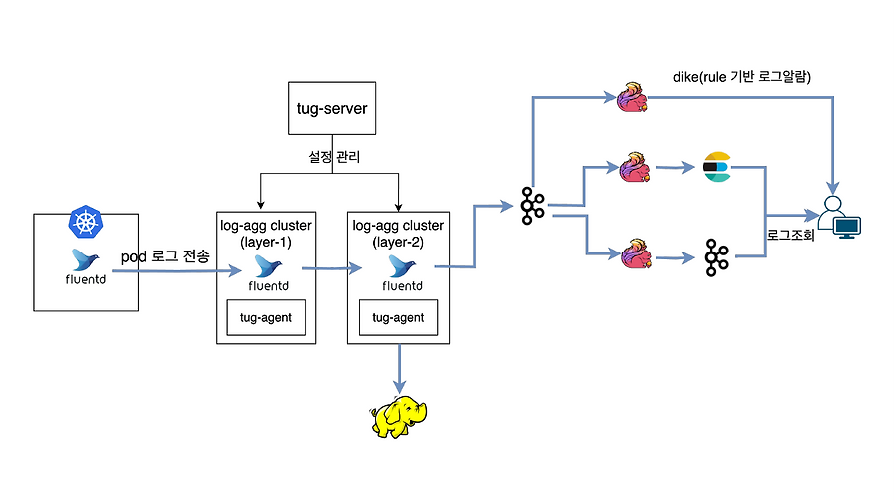

카카오의 내부 로그 수집 시스템 kemi-log와 Fluentd 대체 과정을 소개합니다. 오픈 소스 기반 로그 집계 구조의 전환 맥락을 다룹니다.
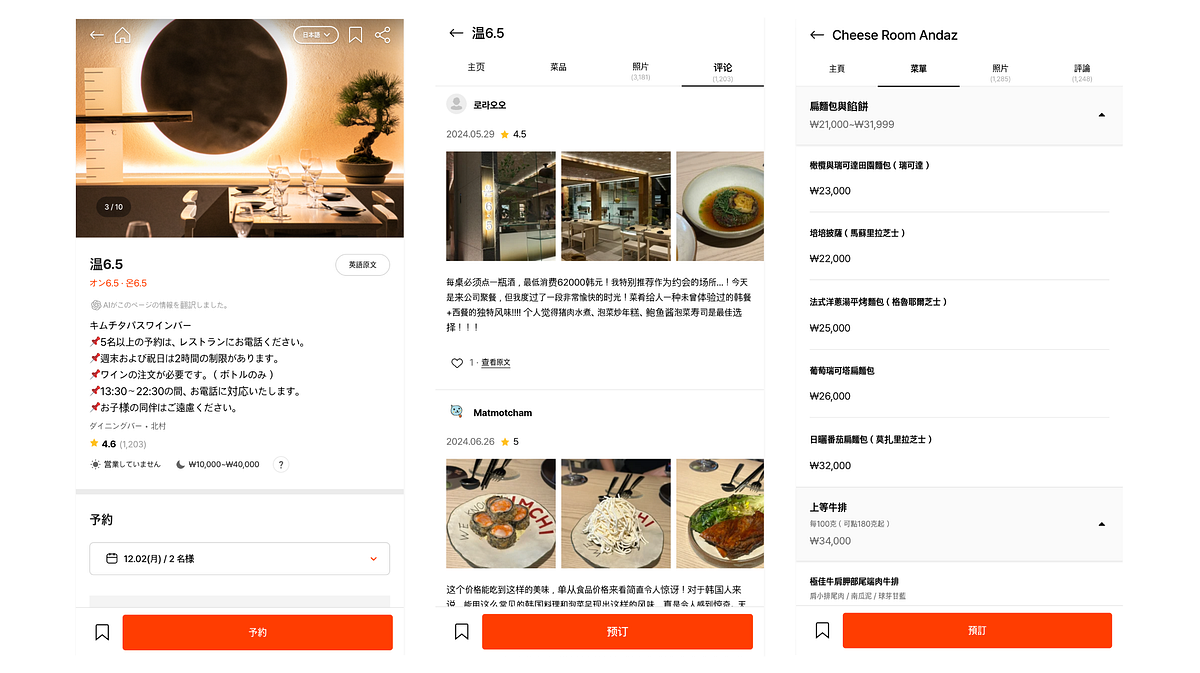

캐치테이블 글로벌은 번역 마이크로서비스와 검수 어드민을 도입해 다국어 레이어를 구축했습니다. 또한 AWS DMS CDC와 Kafka를 활용해 기존 도메인 변경을 중앙에서 번역 요청하도록 설계했습니다.
Spring Kafka의 seek 기능으로 컨슈머를 멈추지 않고 오프셋을 이동하는 방법을 정리했습니다. 분산 환경에서는 HTTP API와 Redis Pub/Sub로 요청을 전파해 그룹 단위 재처리를 구현했습니다.