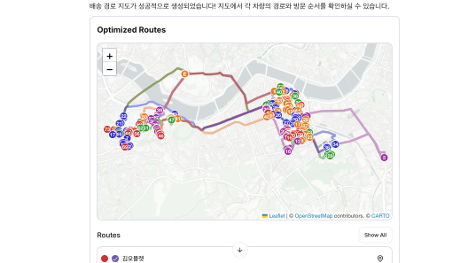

Amazon Bedrock을 활용한 Omelet의 경로 최적화 AI 에이전트, TOAST
Amazon Bedrock을 활용해 경로 최적화 AI 에이전트 TOAST를 구현한 사례를 소개했습니다. 자연어 입력, 다중 에이전트 구조, 시각화와 재최적화를 통해 활용성을 높였습니다.
#Amazon Bedrock#LLM
70005분
Amazon Bedrock을 활용해 경로 최적화 AI 에이전트 TOAST를 구현한 사례를 소개했습니다. 자연어 입력, 다중 에이전트 구조, 시각화와 재최적화를 통해 활용성을 높였습니다.

Amazon Bedrock과 MCP로 기업 AI 에이전트가 공통 도구를 표준화해 쓰는 중앙 허브 구조를 소개했습니다. 분산 개발과 중앙 거버넌스를 결합해 확장성, 보안, 운영 효율을 높이는 방식입니다.
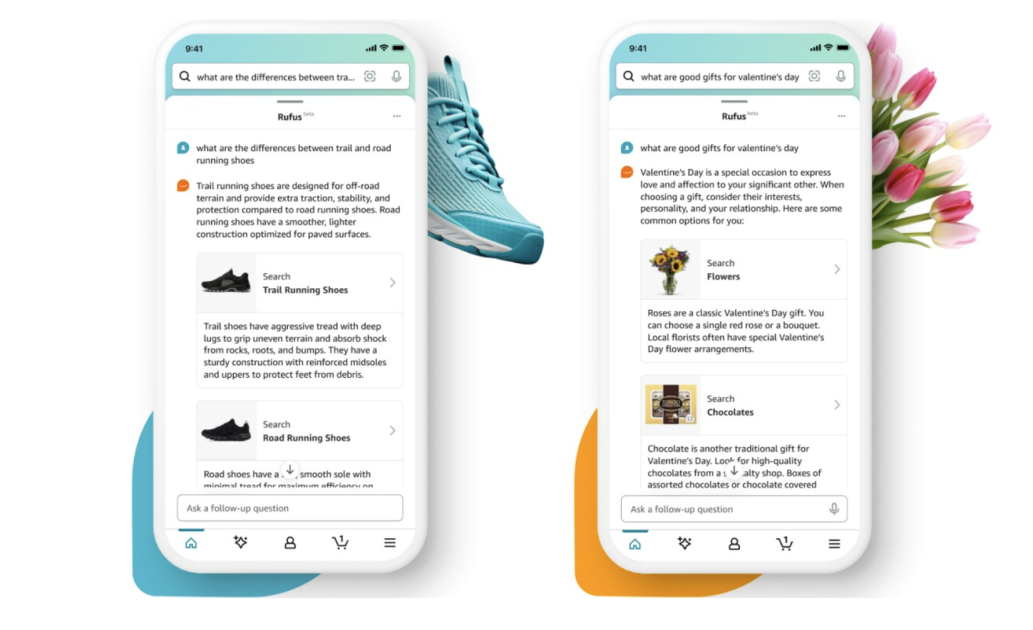
Amazon Bedrock과 AWS 서비스 조합으로 Rufus 같은 쇼핑 어시스턴트를 구현하는 방법을 소개했습니다. Tool 최적화, 컨텍스트 사전 로딩, prompt caching으로 응답 속도를 줄이는 방식을 설명했습니다.

OpenSearch Service의 AI Search Flow 빌더로 Semantic 검색과 멀티모달 RAG를 빠르게 구성하는 방법을 소개했습니다. Ingest/Search Pipeline과 템플릿, AI 제공업체 연동으로 미들웨어 없이 검색 기능을 확장하는 흐름을 설명했습니다.

당근페이는 Bedrock 기반 Text-to-SQL에서 메타데이터와 샘플 쿼리, 용어 사전을 체계적으로 수집·관리하는 방식을 소개했습니다. 또한 검색 최적화와 SFT, MCP 확장으로 정확도와 활용 범위를 넓혀갈 계획을 공유했습니다.

당근페이는 브로쿼리라는 내부 Text-to-SQL 봇의 배경과 아키텍처를 소개했습니다. 자연어 질문을 SQL로 바꾸고 컨텍스트를 보강해 데이터 활용 장벽을 낮추는 구조를 설명했습니다.

Amazon Bedrock Guardrails의 한국어 개인정보 검출 지원과 활용 방법을 소개했습니다.\nApplyGuardrail API로 이름, 주소, 전화번호 등 다양한 민감정보를 탐지하는 예시를 보여주었습니다.

Amazon Bedrock과 Amazon Nova를 적용해 사진 기반 AI 콘텐츠 생성 구조를 개선했습니다. 컨테이너를 경량화하고 처리 시간을 크게 줄여 빠르고 효율적인 서비스 운영을 가능하게 했습니다.

Amazon Bedrock Agents와 MCP를 Lambda와 CDK로 연결하는 서버리스 통합 방법을 소개했습니다. MCP 도구를 OpenAPI로 변환해 Agent의 Action Group으로 쓰는 구현과 배포 절차를 정리했습니다.

Amazon Bedrock의 프롬프트 캐싱 동작 방식과 적합한 사용 사례, 구성 방법을 설명했습니다. 또한 usage 메트릭과 CloudWatch로 캐시 효율을 모니터링하는 방법을 안내했습니다.

티오더가 Amazon Bedrock과 MCP로 운영 플랫폼을 구축한 사례를 소개했습니다. 자연어 기반 도구 호출과 알람 자동 요약으로 장애 대응과 운영 효율을 높였습니다.

AWS Bedrock Agent와 Support Automation Workflows를 결합해 AWS 리소스 문제를 자연어로 진단·자동화하는 방법을 소개했습니다. EKS 워커 노드 조인 실패 사례를 중심으로 런북 실행, 결과 해석, 조치 안내 흐름을 설명했습니다.